前言
GlusterFS 是一套OpenSource的Distributed File System. 簡單來說,他可以把多台多個儲存資源串連起來變成一個或多個Pool。每一個Pool支援Global Namespace/Common Namespace的特性,也就是說,在不同地方掛載同一個Pool看到的會是相同的東西。有使用過GlusterFS的人都會發現,以Default的Configuration來跑GlusterFS將會得到慘不忍睹的笑能。因此在這邊分享及驗證透過修改GlusterFS不同的參數對於效能的幫助
Configurations
修改的參數我把他分為三類,分別是IO,Cache和Network的參數修改。
I/O
io-thread-count (16-> 64)
最多同時IO的Thread個數。數字越大就允許越多同時的R/W。特別是當你有RAID的時候可以調高這參數。Default值是16write-behind-window-size(1MB-> 1GB)
Cache
cache-size (32MB-> 2GB)
read cache的Size。Default值是32MB
cache-max-file-size (-> 16384PB)
設定最多file cached的大小。
cache-min-file-size (-> 0)
cached file最小的大小。
Network
auto tuning(-> disable)
OS會根據網路的throughput來動態調整TCP的window size。但是如果是在穩定的Lan環境這功能是用不到的,因此關閉他來避免奇怪的問題。
Performance Testing
上述列了幾個Tuning的參數,接下來實際針對每個參數的調整來驗證改善的成效。
Experiment Environment and Method
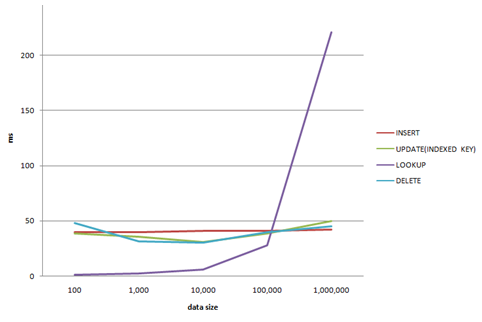
實驗的環境是兩台Server串成一個GlusterFS cluster。 然後在一台Server mount起來,利用iozone來驗證效能。三台的規格都一樣如下圖。

Experiment Configuration
重新歸納一下調整個參數並且給每一個case做編號。

Experiment Result
Write
從寫入的結果來看,在調整了write-behind-buffer後效能有得到非常大的改善。而理所當然的,record size會影響整個throughput。在record=1024KB的時候有較好的結果。

ReWrite
在rewrite的實驗和write有相近的結果。一樣是透過調整write-behind-buffer 來得到效能的改善。

Read
在Read測試當中,可以發現在record size比較小的時候,關閉tso, gro和gso會有較快的效能。不過這個結果應該與網卡及driver有關。

Re-read
Reread與read有相近的結果。在大record size時一樣能得到較好的throughput。

Conclusion
write-behind-buffer很明顯的改善了寫入的速度。我想這就跟在NFS sync/async的差別一樣吧。
在這次的實驗中,沒有RAID 卡也沒有做multi-IO的測試。猜想應該是這個原因才看不出io-thread-count的效果。