The problem
以MySQL為例,在一個table裡面存放10,000筆資料絕對不是問題。但是,當我們的資料上升到十萬筆、一百萬筆甚至一千萬筆,這個時候對資料庫的影響是什麼?當使用者數量一多,資料庫是否依舊能夠在一定的時間內回覆使用者的要求呢?


Traditional Solution
傳統的解決方法不代表是個落伍的、被淘汰的方法。相對的,是一個被證明可以有效解決是個能夠在Production中實作的一些方法。而事實上,大多數的網站仍舊使用這些方法來解決既有大資料量的問題。
Pros and Cons
那麼,partition和sharing各有什麼優缺點呢?Partition
大多數的資料庫其實都已經支援了Partition。Partition的設定方式主要是告訴資料庫要以哪一個column為依據,設定切割的條件。例如int的欄位,可以設定成1~1000為一個table、2000~3000一個table、剩下的一個table。
Partition相對於sharding最大的好處是不需要重寫SQL Logic。資料庫會根據搜尋的條件至相對應的table做query。
但最大的缺點是,儘管是切割成多個table但仍舊是放在同一個database。通常,隨著資料量增加也代表使用者變多了,當然request也變多了。資料庫的效能仍舊受限於該台資料庫所能提供的throughput。

Sharding
Sharding顧名思義的就是將一個table的資料切割放置到多台資料庫中。在實作上,我們可以自己改寫SQL Logic根據我們切割的條件來決定該request要發送到哪一台database。或者,我們也可以看到有許多framework來幫助你完成這件事。例如,MySQL Fabric, Vitess, Gizzard, Jetpants等等。
Sharding好處是資料庫的throughput可以隨著資料庫實體的增加而提升也就是scale out的solution。但最大的壞處是,因為資料散落在不同的資料庫,因此你可能做不到join沒有ACID transaction而且因為所有的查尋會因為資料切割的條件變得更複雜。

How about Big Requests?
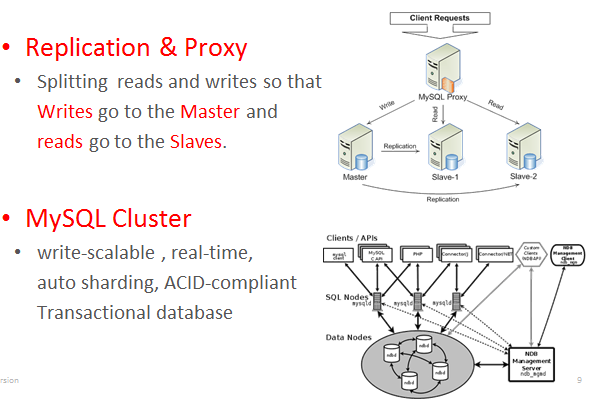
前面有提到,資料量的提升通常也代表使用量變多隨之而來的request也變多了。假設我們已經把資料shard到不同資料庫了,我們要怎麼分散流量呢? Open Source的Load balancer solution是 HAProxy, Nginx或是MySQL Proxy(beta),當然也可以購買貴鬆鬆Hardware load balancer。
另外,MySQL也有MySQL Cluster可以做到load balancer、auto sharding等等。不過就不在本篇的討論中了。
沒有留言:
張貼留言