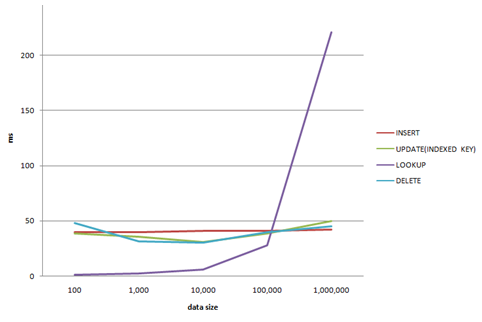
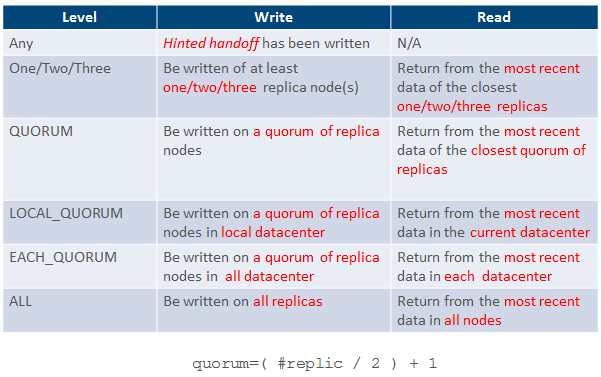
前一篇介紹了Cassandra,而在這裡將繼續介紹Cassandra。
HBase
Hbase是一個Apache top-level的project。他強調的是CAP理論中的CP也就是consistency 和Partition tolerance。
HBase Data Model
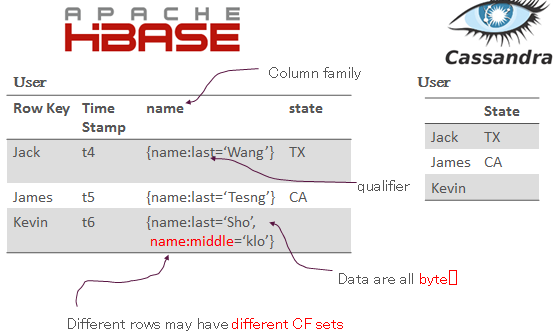
既然前一篇介紹了Cassandra,那麼在這裡就以Cassandra的範例來比較Hbase和Cassandra的不同。
Hbase最大的不同是,他的每一個CF(Column family)即為一個map,而每一筆資料的CF的ket set可以是不同的。而另外一點是,在hbase裡,所有的data都為byte array。
HBase Data Path
Hbase有一張很嚇人的圖,它的特點是箭頭特別多。但是我們可以很簡單的理解這張圖
以下圖為例,Hadoop的Data node其實就是很多台可以存放data 的node。以上圖為例,負責回應request的Hbase 節點有兩個。
P.S. Hbase是可以把資料存放在local disk而非HDFS不可的。
使用者(client)會先留到zookeeper,zookeper會將使用者導到其中一台hbase server。使用者Insert依資料時,hbase會先存成hlog(在損毀時可以roll back)然後存到memstore(可以想像成memory 的小database)接著把資料存到HDFS中稱作Hfile。
NoSQL DON'Ts
在NoSQL風靡了幾年之後,開始有人反思:到底NoSQL真的有比傳統的RDBMS好嗎?或者說,我們真的需要NoSQL嗎?
在選擇之前,必須要先了解NoSQL 做不到的事:
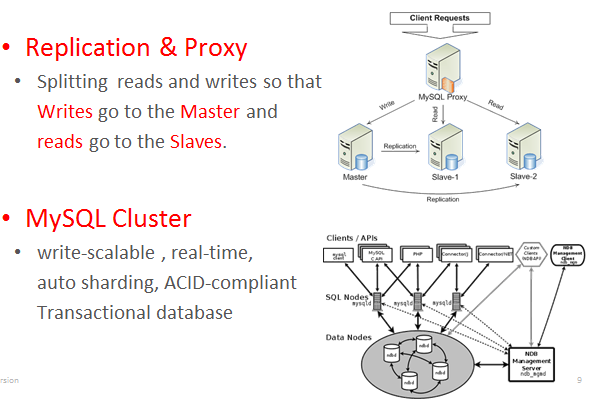
另外一個迷思是,很多人認為在大資料的時代下,傳統的RDBMS是無法應付的?真的是如此嗎? 以Facebook為例,他們是使用sharding來存放使用者的post。你的資料有比他多嗎?